Clover rode a rising trend of health-conscious dining into a rapid expansion, opening dozens of brick-and-mortar stores throughout the region. But as interest in meat alternatives faded in recent years, the company was unable to maintain its lofty vision.
Changing consumer tastes were only one factor in the collapse. Muir and the company’s current management team blamed Clover’s demise on a restaurant economy that has been reshaped by remote work, inflationary prices, and rising operating costs that have affected all of Boston.
But Clover’s demise, investors say, was foreshadowed for years. Documents show a visionary company squeezed by mounting financial pressures as management focused on growth.
Ingredient costs, the company said in a newsletter to customers on Tuesday night, are 30 to 50 percent more now than just two years ago.
“Our local farms are raising their prices,” Clover chief executive Julia Wrin Piper, who has led a turnaround she said has represented a “steady march toward sustainable profitability.” “We simply can’t keep up with inflationary pressures.”
About 170 people will lose their jobs, and leave a hole in the city’s restaurant scene for diners.
“It really seemed like the future of food,” said Kelly Andreoni, a longtime vegetarian and Clover fan starting in its early days. She recently returned and found the experience disappointing. The restaurant was dirty, she said, and quality wasn’t there. “We knew it wouldn’t be long before they closed.”
Justin Alpert, a Boston University professor and restaurant architect, said he regularly went to Clover for falafel. When other fast casual chains popped up that served similar food, ingredients weren’t from local farms, he said.
“Unfortunately, sustainable practices and use of quality products come at a literal cost,” said Alpert. “They chose to go down with that ship in lieu of selling out.”
Muir exited as CEO in late 2023. (He said he resigned; Piper said he was terminated.) A month later, the company filed for bankruptcy protection — emerging the following year with what it described as a clean slate and a desire to open even more stores.
Kitchen staff were hard at work at a Massachusetts Avenue Clover location in 2015. Matthew J. Lee
Documents filed in bankruptcy court showed Clover had about $792,000 in listed assets and about $3.85 million in liabilities. It didn’t own any of its restaurants’ real estate, and a meaningful chunk of what the company still owned — roughly $253,000 at the time — was in food and supplies.
The startup could no longer pay the leases on its new commissary in Hyde Park and several of its restaurants. It had raised $1.8 million earlier in 2023, cut payroll by 43 percent, and unsuccessfully tried to renegotiate its leases. Management also failed to secure a second round of funding that August.
Ron Shaich, the founder of Panera Bread and a Brookline native, was an early investor in Clover. When reached by text, Shaich was blunt about its demise: “I walked away many years ago from the investment when I lost faith in management and the board’s capacities, focus and decision making.”
“The results speak for themselves,” said Shaich, now a major investor whose portfolio has included fast-growing chains such as Cava and Tatte Bakery & Café.
John Pepper, who founded local fast-casual chain Boloco in 1997 and was also an early Clover investor, said he foresaw Clover’s end when he sold his shares at a 50 percent discount at a loss in 2019.
“Am I surprised? No. The structural issues were visible years ago,” said Pepper, who pointed to real estate and overhead costs as some of Clover’s biggest problems. It leased expensive storefronts that needed high volumes to work. That’s “fine when you’re growing, and have exceptionally strong-stomached backers — such as McDonalds for Chipotle — but brutal when you’re don’t have those things and things don’t go exactly according to plan."
Clover’s overhead, he said, was carrying a much bigger company than the one that actually existed.
“Once growth stalled, the math stopped working and the cuts came too slowly,” said Pepper.
Coming out of the pandemic, workers were slow to return to the office, which led to a decline in corporate catering and lunch sales. At the same time, “the cost of labor literally doubled, the cost of utilities doubled, real estate taxes in the city doubled, rents continued to escalate every year,” said Muir. “Restaurateurs find themselves with many more expenses than they ever had but less sales than they ever had.”
“It’s a difficult equation to make it all work,” he added.
Clover’s management had hoped to find a buyer that could keep some or all of the business going. Some of those conversations remain ongoing with what Muir described as a mix of potential buyers. He and Piper declined to name any of the parties.
“We are actively having these conversations that we have hope around ... especially now with the news out,” said Piper, who said she was brought in to replace Muir in 2023 because the company was facing imminent liquidation. “The company has survived a lot of hard periods, one of them we’re grappling with now.”
Piper said she informed Clover’s board, which Muir sits on, last week that “in order to operate responsibly, we had to wind-down operations.”
Muir said it was not until this week that he learned the details of when stores would actually shut down permanently.
“I didn’t know I couldn’t eat at a Clover restaurant this coming weekend until just a few days ago,” Muir.
The Clover restaurant in Harvard Square in 2011.Essdras M Suarez/Globe Staff
Megan Pileggi, Clover’s former director of human resources and development, said she was attracted to the company’s mission of sourcing from little-known local farmers.
“I really believed in it,” said Pileggi. “We all felt like we were part of something much bigger than ourselves.”
But she also saw the problems before leaving in 2019 after nearly 10 years: “We were really trying to ramp things up to go into a new markets, and like, that was an investment that wasn’t right for us.”
In August 2023, Clover closed its Copley Square. At the time, management said it was Clover’s poorest-performing location, losing $350,000 annually over the past few years. Its rent was also $350,000 a year.
Clover’s shuttering also comes as consumers move away from plant-based foods and artificial meats to focus on real meats and dairy.
Matthew Britt, a culinary professor at Johnson & Wales University, compared the restaurant industry to a roller coaster. “Things come up and down. The same goes for plant-based dining.”
“It makes you wonder if Clover got too big,” added Britt.
Muir said in 2014 that he expected Clover to one day be “more profitable than Chipotle and bigger than McDonald’s.”
On Tuesday, Muir didn’t backpedal.
“That was the ambition for the project that Clover was. That was what the world needed,” said Muir, now the CEO of El Nacho, a tortilla chip manufacturer in Waltham. “I wish we had more success getting to that.”
Fivey Fox by Joey Eills — Silver Bulletin illustration
Last Thursday night, I was working late, trying to put some of the finishing touches on our forthcoming World Cup model — and actually looking up an article I’d written for FiveThirtyEight in 2014 about my previous soccer model, SPI. Although the quality of the archive has gradually deteriorated since Disney shut down the site in 2025 (I left two years earlier in 2023), at least our text-based articles were mostly still there, or so I thought. Instead, I was auto-redirected to ABC News’s home page, which looked something like this:
Sometimes weird things happen on the internet late at night, so I resisted the temptation to tweet something about it. But one of my former colleagues noticed the same thing on Friday. ABC News hasn’t made any public comment that I’m aware of — they declined to make a statement to the New York Times, which wrote about FiveThirtyEight’s disappearance. It’s possible that they have something up their sleeve, I suppose. But presumably, this was either intentional or willfully neglectful. All of the former FiveThirtyEight site from my nearly decade-long tenure at ESPN/Disney/ABC is gone.1
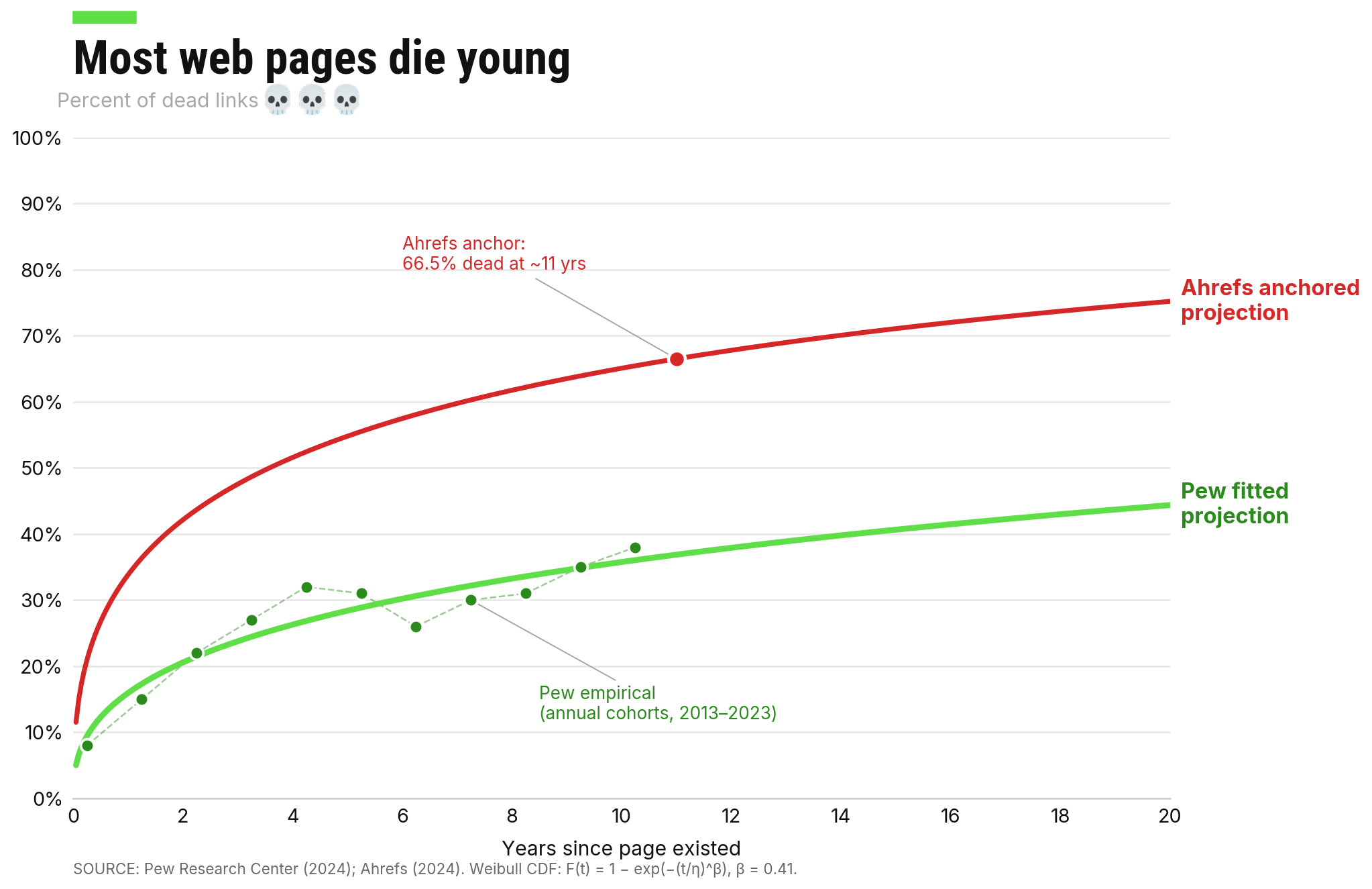
It’s common to read things like: “what happens on the Internet stays on the Internet”, the notion being that you can never escape your digital past. But this isn’t really true. A Pew study of a random sample of Internet links conducted in October 2023 found significant “link rot”: almost 40 percent of links that had been active 10 years earlier were broken. And that’s probably an underestimate: the study was based on the Common Crawl web archive (the same one that AI labs use to train their models), which is quite comprehensive but probably contains some bias toward more prominent sites. Another study by ahrefs found a two-thirds attrition rate for web links after 11 years.
Yes, you can still access (for now) Disney-era FiveThirtyEight content via the invaluable Internet Archive, and pre-Disney-era content from The New York Times (which I partnered with from 2010 through 2013). And obviously, we’re trying to recreate some of the most popular parts of FiveThirtyEight at Silver Bulletin. The election models and polling averages are here, and new-and-improved versions of the sports models (PELE, ELWAY, COOPER) are gradually returning too.2 Galen Druke, Clare Malone and I have even been getting the old podcast crew back together for live shows.
We really do appreciate your support in the form of free or paid subscriptions.
To be clear, we’re not trying to create a full-fledged version of FiveThirtyEight. Having a smaller team gives me more time for creative work, such as writing and building models. In fact, post-Disney life is better along pretty much every quantifiable and intangible dimension.
Still, these abstractions about “link rot” don’t quite capture the feeling of seeing so much hard work erased.
200,000 hours of work erased
Here are some numbers roughly in the right ballpark: during the Disney era, which lasted about 10 years, FiveThirtyEight published about 20 stories a week. Let’s say that each story took about 20 hours to produce between research, writing, graphics and editing.3 Do the math, and that works out to about 200,000 person-hours of work that ABC News just deleted.
What’s probably harder to see from the outside is that none of this was ever smooth sailing: that content was produced through a lot of blood, sweat, and tears (sometimes literally on certain election nights).
Maybe the deletion of the site has me feeling wistful, but I thought I’d write about the various phases of FiveThirtyEight, including some inside-baseball stuff that I’ve never really talked about publicly.
I’m just going to speak from my vantage point, not on behalf of the several dozen people who worked on the site in its various iterations. I’m not going to talk about competing editorial visions or personality clashes or any of that, though we had our fair share of newsroom drama. Instead, this is intended as more of a business school case study: a study of a large corporation, The Walt Disney Company, behaving in an incredibly neglectful way toward a smaller brand it acquired, with dozens of employees who worked exceptionally hard despite constant existential uncertainty.
I want to state one thing up front: I think FiveThirtyEight could have been a highly valuable business if it had been managed more carefully. I know the New York Times considered FiveThirtyEight a valuable part of its subscription offering. I know some of the sharper minds behind subscription-based businesses tried to acquire FiveThirtyEight at various times. And I know the economics of Silver Bulletin, and they’re good. There are challenges: our traffic is highly cyclical, increasing severalfold around major elections and sporting events. Still, my guess is that FiveThirtyEight could have had north of 100,000 paying subscribers by this point: in the same general ballpark as The Free Press, which recently sold for $150 million.
The thinking at Disney is presumably that they invested a lot of money in FiveThirtyEight and were left with nothing to show for it. But to my mind, however much they spent on FiveThirtyEight, they never invested a dollar in it. There was never really any effort, or even any pretense of trying, to make it a profitable unit of the company. At one point, other senior staffers and I basically begged Disney to turn on a paywall, figuring this could provide some security, and were told, essentially, that it just wasn’t worth Disney’s bandwidth to figure out the mechanics of one. We were treated like an unused gym membership: you don’t want to cancel because you think you ought to be hitting the gym, but every month a charge hits your credit card statement and you aren’t getting any fitter.
The origins of FiveThirtyEight.com
I founded FiveThirtyEight.com under the pseudonym “poblano” in March 2008 as a spin-off from a popular series of posts at the progressive blog Daily Kos. For the previous several years, after quitting my corporate consulting job in 2004, I’d had two main sources of income. One of them was building statistical models like PECOTA for Baseball Prospectus, an early adopter of a subscription-based business model that still exists today and has graduated dozens of staffers into Major League front offices. BP had good timing going for it — this was the dawn of the Moneyball era in sports. But the subscription-based offerings were relatively rare at the time. BP churned out enough revenue to support a middle-class income for around a dozen co-owners/stat nerds/writers but not much more than that.
However, I didn’t really care because my real source of income was playing online poker. Yes, there really was a time when you could click buttons for a living and make a pretty good income by working the late shift against what I imagined to be drunk Scandinavians. It seemed too good to be true, and ultimately it was. The passage of the UIGEA in late 2006 essentially cut off new money flowing into the game, the remaining players were getting sharper, and the format I specialized in at the time (limit hold ‘em) was gradually losing ground to no-limit hold ‘em, which I wouldn’t become proficient at until years later.
The UIGEA, passed on the last day before Congress adjourned for the 2006 midterm elections, did pique my interest in American politics, however. I wanted the bastards who had deprived me of a living to be voted out of office, and they largely were, including the chief sponsor of the bill, the 15-term Iowa Congressman Jim Leach.
“Moneyball, but for elections” was a logical enough pitch, but I didn’t anticipate the degree to which FiveThirtyEight.com would become a viral hit in 2008. It helped that the election featured a number of compelling personalities, including a guy whose name I’d vaguely remembered from my time at the University of Chicago: Barack Obama. I ran ads on FiveThirtyEight, and the money wasn’t fantastic by any means, but digital advertising rates were comparatively healthier back then, so it was enough to pay the rent.
FiveThirtyEight, de-anonymized midway through the 2008 cycle, drew a lot of media attention, particularly after the model’s highly confident “call” that Obama would defeat John McCain proved correct. On a train platform on my way back from the MIT Sloan Sports Analytics Conference conference in 2009, I encountered a senior editor at the New York Times who had been in attendance. I’ve long been an admirer of the NYT — my parents in East Lansing, Michigan even had a ritual of walking to the bookstore every day to buy the print edition. Long story short, the NYT made a good-enough offer. The finances weren’t fantastic, but it was an extremely clean deal: I was a contractor, not an employee, so I was free to pursue other sources of income, and I regained full ownership of the models and the other IP after I left the Times.
Honestly, I expected to renew with the Times. At the risk of being immodest, the 2012 election forecast had been a smashing success, with the FiveThirtyEight model famously “calling” all 50 states correctly that year in a stroke of luck that later felt like a bit of a curse. (There was only about a 3 percent chance this would happen, according to the model’s internal logic.) The Times had launched a digital paywall midway through my time there, and its subscription revenues had grown significantly in the 4Q of 2012, coinciding with the Obama-Romney election. How much FiveThirtyEight was responsible for this was hard to say — the Times has had a lot of success without us, obviously — but I had a lot of leverage.
“We” (my attorney and I) basically decided to give the Times an exclusive negotiating window before exploring the market. My keen sense at the time was that the NYT would not be the highest bidder, but I really did like working there, and they deployed me creatively on everything from the Magazine to the book review. The Times was a deeply factional place in those days, though, and the FiveThirtyEight product had both internal champions and internal critics.4 The Times was also in the midst of a leadership transition, and new management tends to want to move on from the old regime’s pet projects, even if they were successful. Although I’d moved to an apartment within walking distance of the NYT office in anticipation of a new deal, the Times dragged its feet to the point where we eventually felt like we had no choice but to test the market.
We wound up signing up with ESPN. It doesn’t seem like the most obvious fit now, but this came during an era when ESPN basically thought of itself as the best business in the world, guaranteed an annuity based on cable rights fees. Its then-president, John Skipper, had highbrow ambitions for premium products, notably Grantland. Grantland, built around another spiky founder, was quite explicitly a precedent for FiveThirtyEight @ Disney. I don’t catch up much with Bill Simmons these days, but he was a helpful consigliere during the negotiations, offering reliable advice on navigating any and all things Disney-related.
For the record, other offers we seriously considered came from NBC News, Bloomberg and the Times. The latter two would probably have been better fits, because they’re basically in the same business as Silver Bulletin/FiveThirtyEight: selling premium subscription products.5 ESPN and NBC are primarily television networks, by contrast. I’ve never really liked going on TV, and it’s probably my worst medium despite some genuinely good-faith efforts by ABC News to make it work.
The early Disney years: mistakes were made (mostly by me)
In hindsight, I chose poorly. Skipper had been fairly explicit that he didn’t really care whether FiveThirtyEight made money: like Grantland, we were essentially a hood ornament on ESPN’s oversized SUV and a “rounding error” relative to Disney’s gigantic P&L.
That might seem like a fantastic situation — Disney’s pitch was basically “we’ll cut you a nice check to be maximally creative” — and I consider myself privileged to have been given the opportunity. But there were several problems with the arrangement.
The b-school way to put this is that there was never brand or incentive alignment — with Disney being very “macro” (it takes huge swings: theme parks, Marvel movies, NFL rights deals) and FiveThirtyEight being very “niche”. Furthermore, the Disney attitude basically seemed to be that “creatives” were sensitive artist types who didn’t care about money so long as they made enough of it, but I’ve always had a fairly entrepreneurial spirit.
But most of all, this sort of arrangement makes you extremely dependent on your bosses’ goodwill, and Skipper abruptly left ESPN one morning in 2017 because of an extortion scandal.
FiveThirtyEight relaunched @ Disney/ESPN in March 2014 to “mixed” reviews. And by “mixed” reviews, I meanmostly bad ones. The launch was kind of a disaster, really. I’ve written before about some of the Mistakes That Were Made, most of which were predictable mistakes that I made. Among other problems, I did too much bragging in the media and didn’t anticipate the extent to which public opinion toward FiveThirtyEight would shift once we became a corporate-backed incumbent rather than an eccentric upstart. We added too many staffers too quickly, perhaps anticipating that we’d never have more leverage to add “headcount” than when we were a new, shiny object for Disney. Relatedly, we put too much emphasis on quantity and not enough on core products.
The core mistake, though, was that almost nobody was thinking about how to make FiveThirtyEight a viable business. We had essentially no dedicated business people or “product” people or anyone else whose job description depended on the site being economically viable. We never developed the muscle memory or the infrastructure to be a commercial product.
Despite all of this, FiveThirtyEight eventually rounded into a very good and popular website, or so I’d like to think. Our 2016 election forecast was literally the most “engaging” feature on the internet, according to Chartbeat, and our podcast received hundreds of thousands of downloads per episode.
But it never quite felt that way. Whenever we felt like we finally had some open runway, we’d encounter an unwelcome hurdle.
In 2015, I was taken aside while walking with my boss one warm spring afternoon and told that Bill Simmons would be dismissed from Grantland. Grantland had a brief and tumultuous post-Bill period but was shuttered completely by late 2015. This was a very ominous precedent: Grantland had literally been in the same sub-unit of ESPN as FiveThirtyEight, with much of the same senior management.
Then in 2016, there was the whole … Trump thing. Being dismissive of Trump’s chances early on in the Republican primary was the biggest analytical mistake of my career, and I think I deserved a lot of blame for that.6 I will insist that our general election forecast did an excellent job that year, though. Our model famously/infamously gave Trump about a 30 percent chance of winning, much higher than prediction markets, other models or the conventional wisdom at the time. That’s not how the rest of the internet saw it, however. It was a difficult election night and a difficult aftermath period. Everyone had their own way of coping; I remember playing an inordinate amount of the EA Sports NHL game and trying to take the Rangers to the Stanley Cup.
We wanted to leave Disney sooner, and we probably should have
Honestly, ESPN took the Trump stuff relatively well. FiveThirtyEight had produced a truly extraordinary amount of traffic in 2016, at least — even if none of it was being monetized. But at some point in early/mid 2017, with my initial contract with ESPN set to expire in early 2018, Skipper called me up to his office one morning and told me basically that FiveThirtyEight could no longer be a thing at ESPN, but he’d work his connections to find a good landing place for it. I don’t know what the impetus was for this — although it came amidst the whole “stick to sports” period at ESPN, and FiveThirtyEight obviously mostly wasn’t sports. For what it’s worth, though, I thought Skipper was relatively sincere, and we did take a lot of meetings.
But the resulting negotiations were fraught. There were plenty of “suitors” interested in a pared-down version of FiveThirtyEight, which would trim staff by perhaps half to two-thirds. For better or worse, I’d chosen to place a big emphasis on staff retention, even though the market consensus was probably right that the business model would be better with a leaner staff. The two main external suitors were The Athletic (later sold to the New York Times) and, confusingly, The Atlantic. I think highly of the leadership at both organizations, and they had the right idea: FiveThirtyEight could be a compelling subscription product even if it wasn’t viable based on web advertising alone.
We came quite close to securing a deal with The Athletic, close enough that the founders came to New York for an entire week of meetings to sort through every detail. I’d expected things to culminate with a handshake agreement and a celebratory lunch before they headed back to California. If you know anything about my organizational skills, they aren’t great, but I thought we (me and the other senior staff) did a reasonably good job of softening the ground for a potential transition to The Athletic and a subscription-based business model. This wasn’t a hard sell because most of the staff would be offered jobs at the new organization.
Long story short: the potential deal with The Athletic hit a last-minute snafu, which there might have been time to work around if there hadn’t been a hard deadline imposed by Disney, but Disney needed a decision from us. The sale process was complex: Disney owned some of the key IP (the trade name and site archive), while I owned some of it (the models). Moreover, Disney was both running the sales process and represented one of the bidders (ABC News). Somewhat bizarrely, ABC, a Disney related party, had entered the bidding at some point midway through the process; apparently, there had been some signals crossed about this in Burbank, and ESPN hadn’t realized that ABC had been interested.
So we put our tail between our legs and signed up for another tenure at Disney, doing our best to make it seem as though this had been the plan all along when it obviously wasn’t. Although ABC News was nominally a better fit than ESPN — they did put me and other staffers on TV more often — I was quite certain at the time that this was going to be our last hurrah at Disney. It became apparent, even before there was any ink on the deal, that while ABC News was happy enough to spend money on FiveThirtyEight with major elections forthcoming, there was the same issue as with ESPN: they weren’t really looking to invest in the property in a way that might make it profitable and sustainable. And even more so than ESPN, ABC News was a dinosaur of a business that attracted mostly older customers and managerial talent.
Nevertheless, the period from roughly 2018 to 2019 was probably the high point of FiveThirtyEight at Disney. It helped that our 2018 midterms forecast basically totally nailed the outcome, offsetting at least some of the stink from 2016. Still, the existential uncertainty about Disney’s loyalty to the site persisted.
This was when we pitched the paywall idea to upper management. Disney batted it around and ultimately turned us down. We never quite got a coherent rationale for why: something something about Disney being busy with its Hulu acquisition and not wanting to launch multiple subscription-based businesses at the same time.
It didn’t make much sense. My content had been paywalled at the New York Times and at Baseball Prospectus before that. Long before Substack came along, it was the business model that works for differentiated, high-quality content. (For “niche sites”, if you will, although elections and sports are large niches.) I don’t know what the paywall would have made, but after a year or two to get settled, it would probably have been comfortably in the seven figures annually: let’s call it $5 million. The cost might be annoying some customers who were used to free content, but we were hardly running any ads on the site anyway.7
What sort of business basically turns down a “free” $5 million? Well, apparently, a company like Disney, a company that made $69 billion in revenues in 2019. If you’re a rounding error when you’re losing a couple of million bucks a year, you’re a rounding error if you’re making a few million also.
The most generous interpretation is that Disney only understands things that operate at very large scales to truly mass-market audiences. ESPN.com had once been the exception to this, full of quirky offerings like Page 2 and Grantland. But it has largely been lobotomized, too, with talents like Pablo Torre and Zach Lowe having been let go.
The long, weird, bitter end
Then came the COVID pandemic in 2020. We thought we were smart by telling staff to start working from home a day or two before official Disney guidance, not realizing that the newsroom would never really be the same again.
Honestly, I think people forget how difficult this whole period was. I consider myself lucky never to have gotten seriously sick or to have lost any close friends to COVID. But there were challenges if you were working in the media at the time: the adjustment to “going remote” and the political “reckoning” that basically any non-explicitly-conservative-coded media business experienced, and all of this coming on top of an election year.
Even as the world awkwardly and unsteadily got “back to normal,” FiveThirtyEight never really did. Key staffers like Clare Malone were let go without any real plan to replace them. Slowly, the oxygen tubes were being removed.
There was also the matter of my contract. The new deal I’d signed with ABC News in 2018 was nominally 5 years long but included a mutual opt-out after 3.5 years, originally timed to December 2021. Either I or ABC had the right to pull the plug, but if neither of us did, the deal would extend through the 2022 midterms by default.
The signals I was getting from ABC News were quite bearish, but they also weren’t quite ready to make a decision. What I wanted, frankly, was to pare down my responsibilities to Disney — and take an appropriate pay cut — in exchange for non-exclusivity. I’d license the models to them for 2022, produce some designated number of columns and TV appearances. But I wanted to be officially free of managerial responsibilities, serving as more of a mentor/founder, and also free to start a Substack and begin building an audience for it.
ABC’s response to this was basically radio silence. There was never any sort of counteroffer or serious conversation about it. Surely, then, they’d exercise their opt-out right, and we’d each go our separate ways in December?
Well, no. Disney repeatedly asked to push back the deadline for making a go/no-go decision, and my agents and I agreed to several extensions until we got tired of the delays.
The eventual, thrice-delayed deadline came on an exceptionally cold Saturday in February.8 I had a late dinner reservation with my sister and some friends, and we went back to her apartment afterward. I checked my inbox in between sips of wine, half expecting to get an email from ABC at 11:59 p.m., but nothing came. I don’t know if they literally forgot about it, but that’s how it felt.
To be fair, I could have opted out also, and if I’d known at the time how much better life after Disney would be, I would have. But I was pretty explicitly in a lame-duck period from that point onward. I’d totally busted my ass for the first seven or eight years of my 10-year tenure with Disney, but in this late phase, I was mostly focused on my book, which I explicitly had the right to work on per my contract.
I received an urgent text message from my boss one morning in April 2023. There had been rumors of job cuts at ABC News, and it could only mean one thing. What was surprising, though, was that while the cuts were both deep and haphazard — while you might have been able to take a go at 2024 with a skeleton crew, you probably wouldn’t have wanted to cut all the managers and editors, as ABC did — they weren’t quite ready to shut down the site entirely. I was not, technically speaking, a part of this layoff, but with only two months to go on my contract, it was safe to assume that they weren’t going to offer me a new deal and I wouldn’t have taken one anyway with the staff gutted and the remaining staffers left in an incredibly challenging place.
To be honest, I’m not sure that ABC News realized that they had no more rights to the models: the license term on the election models expired with my contract.9 But they did eventually hire another “model guy”, G. Elliott Morris, to replace me. I am absolutely not looking to extend a beef with Morris, who, like me, seems much happier with his post-Disney life on Substack. But it’s important context to state that this isn’t the person I’d have hired; we’d had a long-running feud, in fact.
I chatted with my ex-boss at about this point in time and asked if they’d consider discontinuing use of the FiveThirtyEight trade name. Even leaving the Morris hire aside, there were a number of other things I did not like, such as beginning to stylize “FiveThirtyEight” as “538” and replacing our carefully refined site design with an ugly ABC News template. (Even though FiveThirtyEight routinely drove more web traffic than the entirety of ABCNews.com.) There was no more sports section, either. The brand was very much being depreciated, and I didn’t want people to associate this stage of the site with its glory days.
What happened in 2024 isn’t something I’d have scripted, though. Basically, their new election model was literally broken, continuing to show Joe Biden virtually tied with Trump even after his disastrous debate. (Evidently because Morris’s design for it had been overcomplicated. These models are hard to design, by the way.) The model was taken offline for more than a month after Biden dropped out, missing basically the entirety of the Kamala Harris “Brat Summer” period. My understanding is that the new, debugged version had been ready earlier, but ABC News PR was exceptionally sensitive about public perceptions around the model, speaking about it only cryptically in contrast to the transparency the site had been known for.
Meanwhile, I had a good year. Silver Bulletin received more support than I ever expected, and I was all over the media during my book tour. I’m not going to lie: after 10 years feeling jerked around by Disney, the whole sequence was pretty satisfying. But it also proved the point about a subscription-based model being the right call.
ABC finally fully shut down FiveThirtyEight in March 2025, 11 years after its debut at Disney. Eleven years is a long time in the media business, and the site covered one of the most tumultuous periods in American political history with its unique blend of analytics, brutal honesty and irreverence.
Disney refuses to negotiate with me
It would be nice if that work could be preserved for the public record. I don’t know what plans Disney has for FiveThirtyEight, if any. But I did approach Disney a year or two ago, through my agent, about acquiring the remaining IP. I’m probably the logical high bidder, though the value is rapidly depreciating as what’s left of the site falls into disrepair. At a minimum, we’d restore the archive, with prominent links to Silver Bulletin.
We were told to basically get lost: ABC was annoyed with my critical public comments about their management of FiveThirtyEight. It apparently wasn’t a long conversation, so I don’t have a lot more color to report than that.
Hanlon’s Razor states: Never attribute to malice that which can be adequately explained by stupidity. But honestly, I don’t know which explanation is better suited to ABC. During the second half of my tenure with Disney, it felt like they were putting almost literally zero effort into any decisions involving FiveThirtyEight (other than my being featured prominently in their election night coverage10).
The one good thing about the bitter ending is that it prevents the temptation to feel overly awash in nostalgia. Because FiveThirtyEight was always produced with a lot of care, including attention to copy editing and graphics, it tended to impress people as a more smoothly running operation than it actually was. Internally, there was always a lot of conflict: between bright but opinionated staffers, all of whom had slightly different ideas about what “data journalism” was, between staffers and their opinionated boss/founder, between the news cycle and our deadlines, and between pretty much everyone and Disney. The relationship with Disney wasn’t particularly heated, so there weren’t a lot of stories that would make for good movie scenes. But mostly we just felt neglected.
Disney HR did send me a literal Mickey Mouse plaque after I left, celebrating my 10 years as a “castmember”. There was one small problem, though: they misspelled my first name as “Nataniel”.
Although I still own the IP to the original versions of the sports models, most of them were last worked on 5-10 years ago, so I’ve basically decided to do a complete refresh on our suite of sports models instead.
That’s probably about right. The average Silver Bulletin story takes something like 15 hours from start to finish, and I write faster than most people.
The Times is a different newsroom now, both more data-friendly and more pluralistic, but at the time, the main tensions were with the politics desk, which did not appreciate FiveThirtyEight’s implicit criticism of “horse-race” type coverage during what was ultimately a pretty boring 2012 election
We’d also been dismissive of Bernie Sanders’s chances against Hillary Clinton, a “call” that was technically correct but maybe not correct in spirit given that Sanders won quite a few states in a way that foreshadowed Clinton’s weaknesses.
And we’d probably have wanted to hire a couple of staff devoted to things like pricing strategy and customer retention. Let’s call it $400K-$500K/year for two senior staffers. Still a pretty good return on investment.
Disney retained a non-exclusive license to continue publishing the sports models (but not the politics models) in the condition they were in as of my departure. Instead, they fired the entire sports staff and stopped publishing them anyway.
ABC was also constantly begging us to replicate the New York Times “needle”. The needle is an exceptionally challenging engineering and statistical product; we had nowhere near the resources for it, and always found a way to turn them down.
Xi Jinping spent 13 years building a military to rival that of the United States. But the stronger the Chinese forces grew, the less he trusted the generals he had handpicked to run them.
China’s leader, Xi Jinping, during a military parade in Tiananmen Square in 2025 in Beijing.Credit...Pedro Pardo/Agence France-Presse — Getty Images
The purge China’s leader, Xi Jinping, has inflicted on the military elite was plain to see at a recent legislative meeting. A year earlier, state television footage showed around 40 generals in the room. This time, there were only a handful.
Yet Mr. Xi indicated that an upheaval that rivaled those of the Mao era was not over. Stony-faced, he warned the remaining officers to beware of disloyalty.
“The military,” he said, “must never have anyone who harbors a divided heart toward the party.”
It was a rare public reference by Mr. Xi to one of the worst political crises of his 13 years in power: He had lost faith in the military leadership that he had spent a decade remolding.
“When Xi uses the words ‘divided heart,’ they are heavy with meaning,” said Chien-wen Kou, a professor at National Chengchi University in Taiwan. The phrase is found in ancient Chinese treatises that counsel rulers against treacherous generals, including a volume Mr. Xi has kept on his bookshelf.
“Even his most trusted and important confidants have fallen,” Professor Kou said. “Who else can gain his trust?”
The crisis threatens one of Mr. Xi’s great feats: the transformation of the Chinese military into a formidable force with new aircraft carriers, hypersonic missiles and an expanding nuclear arsenal. And it comes as China’s rivalry with the United States has intensified, and as the Trump administration has put American firepower, and its limits, on vivid display in Venezuela and Iran.
China’s war readiness may be disrupted for years by the very cleanup that Mr. Xi has said is necessary to purify and strengthen the ranks. What once looked like a limited crackdown on corruption became a sweeping dismissal of dozens of top officers, and culminated in the downfall early this year of Zhang Youxia, China’s top uniformed commander, who had appeared to be a confidant of Mr. Xi’s.
The final break between them came, by some accounts, when Mr. Xi sought to promote the general leading the cleanup to a position rivaling General Zhang’s. General Zhang objected. Months later, he was out.
Image
Mr. Xi, seated center, watching members of the Central Military Commission take their oath during a session of the National People’s Congress in Beijing in 2023. Most of the generals are now under investigation or were dismissed.Credit...Mark Schiefelbein/Associated Press
The gravity of the campaign was on stark display again this past week, when a military court sentenced two former defense ministers to death, suspended for two years, for bribery. They will probably spend the rest of their lives in prison.
“This is Xi Jinping’s military,” said Daniel Mattingly, an associate professor at Yale University who studies China’s politics and military. “Why does he break the thing that he built?
“It’s not what people would have expected of Xi, even five years ago. Something profound changed,” he said.
The corruption Mr. Xi has been hunting is real. But earlier internal speeches by Mr. Xi, not previously reported in detail, reveal another factor: a leader who saw in any sign of disobedience the seed of a political threat to his rule. He became convinced, analysts say, that the commanders he had chosen to modernize the military could no longer be trusted, their loyalty and effectiveness eroded by graft and cronyism.
Want to stay updated on what’s happening in China? , and we’ll send our latest coverage to your inbox.
Analysts say the upheaval has also exposed the tensions between Mr. Xi’s two imperatives — preparing for combat and enforcing loyalty. Ultimately, Mr. Xi ousted a battle-experienced general who helped remake his military and replaced him with an inquisitor, who is now, alongside Mr. Xi, the sole other remaining member of China’s top military council.
“Xi Jinping’s rule is slowly entering its late stage,” Professor Kou said. “His political calculations change in this stage, his anxieties become increasingly about members of his own inner circle.”
Seizing Control of the Gun
Early on, Mr. Xi appeared determined to avoid the fate of his predecessor, Hu Jintao, who was widely seen to have failed to establish his authority over China’s military commanders.
Mr. Hu’s weakness was exposed in 2011 during a visit to Beijing by Robert Gates, then the U.S. secretary of defense. Mr. Gates asked Mr. Hu about the test flight of a Chinese stealth fighter jet, news of which had emerged that morning on Chinese websites.
Mr. Hu seemed to have no knowledge of it. “The civilian leadership seemed surprised by the test,” Mr. Gates told reporters later.
Mr. Hu’s directives to army commanders were “more like suggestions they would consider,” said John Culver, a former C.I.A. analyst now at the Brookings Institution. “Basically you had a system that was no longer responsive to the party.”
Image
Robert Gates, left, the U.S. defense secretary at the time, and China’s then-president, Hu Jintao, in 2011 at the Great Hall of the People in Beijing.Credit...Pool photo by Larry Downing
After coming to power in 2012, Mr. Xi launched investigations against commanders who had grown wealthy, and overweening, under Mr. Hu, including some previously deemed untouchable because of their status.
In 2014, Mr. Xi summoned hundreds of senior officers to Gutian, a town in eastern China where, according to party histories, Mao Zedong in 1929 established the fundamental principle that defines the Chinese state today: The party commands the gun.
Mr. Xi used that historical backdrop to warn that the Communist Party’s control of the armed forces had eroded to a dangerous degree.
At Gutian, Mr. Xi laid out the problems he had inherited. Faith in the party’s values had decayed. Corruption, cronyism and insubordination was brazen. He cited training exercises so fake that soldiers used shovels and sticks instead of guns.
The Rot
To Mr. Xi, the rot was exemplified by Gen. Xu Caihou, who was a retired vice chairman of the Central Military Commission, a position that had put him near the top of the People’s Liberation Army. General Xu had been placed under investigation, accused of taking huge bribes, including for arranging promotions for officers.
“Xu Caihou always solemnly professed undying loyalty and love toward the party,” Mr. Xi said, according to a previously unreported version of a speech he made in Gutian that circulated inside the military. “But really, deep in his soul he had long ago fallen away from the party and into corruption and depravity.”
Image
Xu Caihou with colleagues in 2004 in Changchun, China. General Xu was accused of taking huge bribes in return for arranging promotions.Credit...Reuters
Mr. Xi was also alarmed by events abroad. He cited cautionary stories of leaders in the Middle East and the Soviet Union who were toppled after their militaries abandoned them in the face of insurrections.
Mr. Xi came to the job with a reverence for the People’s Liberation Army. His father was a revolutionary leader who had fought under Mao. In his early career, Mr. Xi worked as a secretary to the minister of defense. Mr. Xi believed that to instill loyalty in the military to the Communist Party and to him, he had to revive “political work” — the indoctrination, vetting and monitoring that made officers and troops trustworthy.
To drive home the new spirit of discipline that he demanded in Gutian, Mr. Xi was shown eating coarse rice and pumpkin soup, the humble, storied meal of the early Red Army.
“Absolute loyalty to the party rests on the word ‘absolute’,” Mr. Xi said. “It is a loyalty that is singular, total, unconditional and free from any impurities or fakery.”
The Chairman Is in Charge
From his first years in power, Mr. Xi also began entrenching a “chairman responsibility system,” an overhaul that tightened his control over the military by giving him intelligence and control deep into its ranks. He declared his confidence in his own ability to spot the right commanders for promotion.
“The key to building a strong military lies in picking the right people,” he said in an internal speech in 2016, describing how he vetted and spoke to prospects for promotion. “Senior and mid-ranking officers are the backbone for building and running the military, and as chairman of the Central Military Commission, I should personally handle this.”
He also replaced decades-old military regions with new theater commands and he dissolved central People’s Liberation Army departments that he saw as barriers to effective control. His goal was to give China the ability to combine land, air and sea forces to project power abroad, while ensuring that this modernized force stayed unflinchingly loyal.
Gen. Zhang Youxia was among the commanders entrusted with executing Mr. Xi’s vision. General Zhang was a gruff, charismatic officer who had distinguished himself on the frontline of China’s yearslong border war with Vietnam from 1979. He was the son of a revolutionary general who had fought alongside Mr. Xi’s father.
Mr. Xi had earlier promoted him to the Central Military Commission and made him head of the military’s general armaments department. The department was in charge of acquiring new weapons, which are vital to Mr. Xi’s modernization plans, but had also become a mire of corruption, fed by its control over funds and contracts.
Image
A photograph provided by China’s state media showed drones and other armaments in a military parade in Beijing last year. Mr. Xi had entrusted Gen. Zhang Youxia with executing his vision of the military’s modernization. Credit...Liu Xu/Xinhua, via Associated Press
“He came from a privileged Communist Party background, and it showed,” said Drew Thompson, who was working at the Pentagon and met General Zhang in 2012 when he took part in a Chinese military delegation on a visit to the United States. “I think that combination of his background, his combat experience, his self-confidence, his comfort with weapon systems and his openness to change made him attractive to Xi.”
By 2018, Mr. Xi appeared satisfied that his overhaul was paying off. While he acknowledged to the Central Military Commission that problems remained, he said the changes were a “historic transformation” that had “saved the military.”
When Mr. Xi won a third term as leader in 2022, he unexpectedly retained General Zhang in the military commission. At 72, the commander had been expected to step down. Mr. Xi instead made him China’s top general, tasked with pursuing Mr. Xi’s goal of a breakthrough in military capabilities by 2027.
But just over half a year later, in 2023, the veneer of stability cracked. Mr. Xi abruptly replaced the Rocket Force’s top commander and his deputy — an extraordinary move in the arm of the military that controls nuclear and conventional missiles. The purge was never publicly explained. Then China’s defense minister was dismissed without explanation.
Suddenly, Mr. Xi’s transformation of the People’s Liberation Army looked plagued by the same problems of corruption and disobedience that he claimed to have excised.
This time, Mr. Xi brought his commanders to Yan’an, the hallowed base of Mao’s revolution, where Mr. Xi called for a deepening campaign of “political rectification.” In the two years that followed, dozens of high-ranking officers were removed or disappeared from public view.
As the campaign widened, so did the power of Gen. Zhang Shengmin, the commander steering the investigations. He had risen through the ranks despite having little experience in military operations. In the Rocket Force, he was a political commissar, enforcing party loyalty. He was known for his love of Chinese brush calligraphy.
He was later promoted to a newly created agency that investigates graft and disloyalty in the military. His ascent reflected the importance Mr. Xi gave to ideological control and political loyalty, even as he also called for battlefield readiness.
“In Xi’s analysis, failures of readiness stemming from corruption are merely an outgrowth of ideological impurity,” said Joel Wuthnow, a senior fellow at the National Defense University in Washington who studies China’s military. “The rot was perhaps deeper than Xi imagined in 2023, and so he needed to take more drastic steps.”
Gen. Zhang Shengmin’s powers were most likely enhanced by pervasive surveillance technologies that gave investigators more tools to spy into the lives, and financial flows, of officers and their families, said Mr. Culver, the researcher at Brookings.
By late 2025, the purges were reshaping not just the ranks but the balance of power among remaining commanders. Analystssuggested that as the investigations deepened, there was growing turbulence inside the military elite, including between commanders focused on warfighting goals and officers tasked with enforcing political loyalty.
“Xi is trapped in a red versus expert contradiction,” said Mr. Thompson, the former Pentagon official, referring to “red” as loyalty to the party.
Image
Gen. Zhang Shengmin saluting Mr. Xi in March at a conference at the Great Hall of the People in Beijing.Credit...Kevin Frayer/Getty Images
With China’s next leadership transition due at a Communist Party congress late next year, in this reading, Mr. Xi appeared more sensitive to perceived threats to his authority. His top commander, Gen. Zhang Youxia, seemed more dominant, with many potential rivals toppled. But he was not untouched: The investigations had also brought down other generals linked to him, potentially implicating him.
And the chief investigator, Gen. Zhang Shengmin, was rising.
The final straw came when Mr. Xi moved to promote Gen. Zhang Shengmin to vice chairman of the Central Military Commission, said Christopher K. Johnson, a former U.S. government intelligence officer who is now president of China Strategies Group, a consultancy firm.
Gen. Zhang Youxia, backed by his second-in-command, Gen. Liu Zhenli, objected to that proposal because placing an investigator in such a powerful position risked painting the People’s Liberation Army as an unserious combat force, Mr. Johnson said.
Modern Chinese history offers examples of commanders who overestimated how far they could push their leaders. General Zhang appears to have done the same. “Zhang Youxia thought, ‘I’ve got the credentials to say this,’ and it turns out he didn’t,” Mr. Johnson said.
When he and his deputy were removed early this year, the official military newspaper accused them of having “gravely trampled on” the chairman responsibility system, which Mr. Xi had built up to cement his control over the military.
Mr. Xi is not stopping there. In April, he launched a program of “ideological rectification” and “revolutionary forging” within the military — an indoctrination drive, in other words. Mr. Xi addressed the assembled senior officers, described as the first batch of attendees in Beijing, suggesting that the campaign to instill loyalty would roll on.
Television footage of the meeting showed rows of officers diligently taking notes as Mr. Xi spoke. Sitting next to him was Gen. Zhang Shengmin, the enforcer.
Chris Buckley, the chief China correspondent for The Times, reports on China and Taiwan from Taipei, focused on politics, social change and security and military issues.
This month-long journey cannot be meaningfully sped up. Ships can sail faster, but that risks safety and uses more fuel, raising costs. Once the oil reaches land, the refining, loading and transit speeds are constrained by the existing infrastructure.
Japan is fortunate enough to have strategic energy reserves and a robust distribution system that can help it weather the energy crisis. Not every country has those advantages. In those with less developed refining, port or pipeline infrastructure, getting fuel to consumers can take even longer.
And countries that rely on others to refine their petroleum may now face even more delays because of the war as they wait for damaged equipment in the Gulf states to come back online. In March, the Philippines declared a national emergency because of disruptions in oil supplies.
Even once the Strait of Hormuz fully reopens, it may take months for shipping to return to normal. With hundreds of tankers trapped or diverted, clearing the traffic will make trips longer.
And insurance premiums for traveling through the strait — still considered a high-risk zone — will likely make some voyages economically unviable.
It is not just a matter of getting the oil flowing again. Supply chains thrown into disarray by the cutoff will need time to recover. Already, much of Asia is grappling with shortages of petroleum-derived goods like plastics, adhesives and paints.
If you followed along with the recent joyful celebrations of the Artemis cruise around the moon, and took a moment to dive into the photographic archives of the mission, you might have noticed that all of the original images were shared by NASA on the venerable photo sharing service Flickr. What you might not know is… why?
Here’s the TL;DR:
Flickr comes from (and helped start!) the Web 2.0 era, which was based on users having control over their data
Tools at that time began giving creators the power to decide what license they wanted to release their content under, including permissions about how it could be shared, used, or remixed
Because the people who made platforms back then were users and creators themselves, they thought about the long term and wanted to be able to preserve people’s work
After lots of corporate shuffling, Flickr ended up in the hands of a family-owned company, SmugMug, and they made the Flickr Foundation to preserve public photos for the next 100 years
NASA’s images should only be on a service where they can be stored in full resolution, for the long term, dedicated to the public domain — which the other social media apps of today can’t do
The Photographic Record
First, some background for folks who might not know what Flickr is, or who may have forgotten. Flickr is a social sharing site for photography which was founded in 2004, and these days people might say that it shares some of its cofounders with Slack, though back when Slack started, everybody said that the company was started by some of the founders of Flickr. That’s because Flickr was arguably the most influential site of the Web 2.0 era, helping define everything from the user interface design to the bright colors to the easy way that developers could access data from the platform. A lot of the things that we take for granted on the modern social internet, like a friendly “voice” used to communicate to users, were pioneered by Flickr, and then quickly came to be considered standard expectations for the apps and sites that followed. It’s hard to imagine that sites from Tumblr to Grindr would have omitted their final “e”s without Flickr’s precedent.
Flickr spun out of a Canadian gaming company called Ludicorp, founded by Stewart Butterfield (later CEO/co-founder of Slack) and Caterina Fake (later an investor and chair of Etsy). The photo-sharing service was extracted from the pieces of a somewhat unsuccessful attempt at multiplayer gaming called “Game Neverending”, but it retained the playfulness of that game even as it became a social app. Flickr also inherited the fine-grained privacy controls and thoughtful community features of earlier social platforms like LiveJournal — along with being actively, intentionally moderated by actual humans who worked diligently to prevent destructive behaviors on the platform. This meant that, more than 20 years ago, this early photo sharing community typically had better social norms than people see on today’s social media apps. (A little side note: Part of Flickr/Ludicorp’s initial funding was with public money. What a remarkable way to fund lasting innovation!)
With all of these groundbreaking features, Flickr didn’t just inspire lots of other entrepreneurs to create a new wave of Web 2.0 startups, it also attracted millions of users who, for the first time, began taking photos with the primary goal of sharing them online. Prior to this moment, the earliest phones with decent cameras were coming to market (it would be years until the iPhone came out), and other photo services of the time were still often oriented towards taking film to processing facilities, and then having the professionals at those facilities scan the resulting images and post them to a clunky online service where you could tediously click through them in a virtual album. Until Flickr, photo sharing online was essentially still analog, even if the experience was technically happening online.
In Focus
Flickr wasn't a social platform first — it was a photography platform first. That means it was designed to store high-resolution versions of every image, and didn't distort pictures with things like filters. Every image showed details like what kind of camera had taken the photo, and even what specific settings were used to take the shot. People started building communities around the then-new idea of using tags to help them find content by topics online — an idea that would directly influence the creation of hashtags on Twitter a few years later.
Another core idea of the time was a firm belief in open data: people should own and control their own work. Eventually, some experts (including a then-teenage Aaron Swartz, who we'd later talk about in the early days of Markdown) created a set of standards called Creative Commons licenses, now maintained by an organization of the same name. Flickr made it easy for users to describe what permissions people had for reusing or remixing any photos they posted. (I was helping out with a blogging platform back then, and I think we were the first tool to support this stuff. It felt like a big deal at the time!)
People's Flickr images started popping up in corporate PowerPoint presentations or commercial advertising almost immediately. A little sidebar: the incredibly positive and generous intent of these open licenses has since been exploited by extractive Big AI companies, who ransacked all of the images on Flickr that had permissive licenses without any consent from, or compensation to, the creators. That might be legal by most readings of the licenses, but if you have hundreds of billions of dollars and don't think you should at least have a conversation with the photographers whose work you're using, you're probably an asshole.
Archival Prints
Our close-knit community of people building the new era of web apps was keenly aware that our users were creating culture. This realization brought a huge amount of responsibility — not just in enabling users to express themselves, but in thinking about the long term for people's ownership of their works. Public institutions had just begun to use these platforms, which meant that the content being shared wasn't just a nice picture to look at: it might be socially or even historically significant.
What happened in the years that followed was… a lot of corporate machinations. Flickr got bought by Yahoo. Flickr's founders left Yahoo. Yahoo got bought by Verizon. You can imagine how all of that went; the details aren't all that important, except to say that by the time Instagram launched, Flickr had begun to fade into obscurity. People were focused on mobile phones instead of the desktop, on sharing square images with filters instead of full-resolution photography, and on connecting socially instead of caring about photos as art or a cultural record. Nobody would post the canonical historical photo of an event with a Valencia filter on it. Most of Flickr's users moved on, rarely checking their old accounts — until a family-owned photo service named SmugMug bought the service from Yahoo. A human-scale operation with some actual heart and a love of photography was a much better home for the platform than some random division of Verizon.
Commons Sense
In 2022, the new team at SmugMug that owned Flickr decided to focus on Flickr’s larger place in culture. Many major institutions around the world had chosen to archive their public photos on Flickr because of its superior support for high-resolution imagery, its unique ability to declare explicit legal licenses (including public domain licenses), and its long-term reputation for reliably hosting content without any of the harms or abuses that typical social networks had inflicted on users. Museums around the world had entire catalogs on the platform, and governments routinely used it to document their public events. When I had a photo taken at an official White House event with President Obama, his team sent me the final image afterward by sending me a Flickr link; when Zohran Mamdani met King Charles, the NYC Mayor’s Office shared those pictures on Flickr, too.
The Flickr team at SmugMug did something special with their responsibility about these public works, due to their cultural significance to the world. They made the Flickr Commons, and brought in a team with expertise in digital archiving and community. This is a project of The Flickr Foundation, designed to preserve digital legacies, and begun in collaboration with no less than the U.S. Library of Congress (back before that was an institution under siege.) They are developing a hundred year plan for how to care for these works, which is virtually unheard-of in the digital world. (You should absolutely donate to support the Flickr Foundation in their mission to preserve these vital public resources for many years in the future.)
It’s in this context that NASA has long been sharing its imagery on Flickr, for all of its missions — not just Artemis II. There’s even a special section for NASA on The Commons. And since everything is provided in incredibly high-resolution and has every single detail about the photo and how it was taken, it’s possible to combine the information about the photo with other data and create amazing resources like this beautiful timeline of the entire mission. You can see Hank Green’s wonderful narration of his inspiration and creative journey behind the timeline right here:
Why Not With Us?
Anybody who’s read my site for a while knows that I’m a huge proponent of owning your own website, and having your own content live there. Shouldn’t NASA, of all institutions, have their photos live on their own nasa.gov website? Well, yes! But.
One complication is that many large institutions, especially ones that have developed complex processes for good reasons, like government agencies and big businesses, often have trouble maintaining public-facing web infrastructure over long timeframes. Running a website that millions of people can access requires constant updates and maintenance, guarding against a never-ending onslaught of security challenges (a task that’s rapidly getting more difficult!), and the internal knowledge on how a site was created in the first place often leaves when employees do.
In contrast, platforms that are run by technically fluent, well-intentioned and thoughtful technologists can be very effective in maintaining content over a timescale of decades. The SmugMug team has been very thoughtful in managing both their business and their technical infrastructure in order to sustain Flickr’s public archives for years to come. (Though, as mentioned, you should still donate to ensure they can keep doing so!)
What’s more painful is the more recent threats to public stewardship of this kind of content. The traditional authoritarian impulse to destroy or falsify the public record has not spared the digital realm under the current administration. Wide swaths of the government’s websites have been erased, taken offline, or had their content modified to either delete or adulterate the content. Leaders who regularly post AI slop on their social media accounts, and who have begun posting lies and distortions on major websites like the White House’s, will of course not hesitate to modify or remove photos from public archives as well. By having the public’s images preserved in an independent archive in standard formats, we increase the likelihood of future generations being able to access accurate copies of these historical records.
We’ll be glad to have archives like Flickr’s in the future, and people around the world will be glad for its place in archiving even much more mundane aspects of culture.
Taking off
I was honored to get to reflect on my long history with Flickr, and with online community, in an interview with my old friend Jessamyn West, for the Flickr Foundation’s blog. In a conversation that unspooled over a few months, I think we covered so many of the themes that resonated in what I’ve mentioned here, and what struck me most was how much I wanted a new generation of people on the internet to have their own version of the communities and experiences that we got to have when sites like Flickr were first being made. People still cherish those values!
The beautiful thing about communities and platforms like Flickr is that they remind us that not everything on the internet has to be ephemeral, not everything on the web has to be hyper-commercial. Sometimes a bunch of decent people can do a good thing for the right reasons, and the result of that work can persevere for decades. Then, others who do some of the most ambitious and astounding things imaginable can build on that work to inspire us. And then, some more regular folks can build on top of that and help us waste a little bit of time just clicking around on something fun. That’s what the internet is supposed to be about!
This isn’t just about recounting old web lore — this is about explaining the internet we have right now. Hank’s timeline site is brand new, entertaining a whole new generation, and probably the majority of the audience who are looking at it weren’t even born when Flickr was first conceived. But the reason he can build that site is because of the values and the inventiveness of the team and community who created a platform like Flickr — and because those kinds of values are durable. They might not be as loud or flashy, but they are still everywhere, quietly enabling a lot of the things we enjoy most every day.
Public dollars helped make a fascinating community, then public dollars enabled a breathtaking journey into space, and then a public commons helped a creator make a novel way to explore that journey. Lots of people chose, over and over, to be generous with their genius. These are all gifts that a bunch of strangers gave each other, over hundreds of thousands of miles, and many years. Inspiration is all around us!
Life was different in the 1950s. Homes cost less than a quarter of what they do now. Living room TV screens weren't much bigger than a modern laptop. Construction was starting for the Glen Canyon Dam. Humans had yet to travel to space.
Someone who grew up back then can tell you something else: Winters were colder and longer.
Over the past seven decades — the span of the average human life — the number of freezing days has shrunk by weeks in most places across the United States.
Minnesota: Dog sledding, ice fishing, pond hockey
“If you're going to live here, you can either shut yourself in for six months, or you can find a way to thrive. And a lot of people do that,” said Kenny Blumenfeld, a senior climatologist at the Minnesota State Climatology Office.
But winters in the Midwestern state are not what they used to be. On average, they are getting warmer.
It doesn’t mean every winter is warmer than the last, Blumenfeld said, adding that there are ups and downs from natural events like El Niño, but for a state that relies so heavily on winter, the inconsistency can still have consequences.
“It's kind of like [an] unnerving sense where we can't depend on winter,” Blumenfeld said.
Warmer winters have disrupted many events, big and small. In 2025, the John Beargrease Sled Dog Marathon, a 300-mile race, was postponed for two months because the lack of snow and ice had made the course unsafe. In 2024, the U.S. Pond Hockey Championships, in Minneapolis were canceled because warm weather made the lake ice unplayable. In neighboring Wisconsin, the American Birkebeiner ski race also has been shortened and canceled in recent years.
Minnesota’s lakes have lost an average of 10 to 22 days of ice cover in the past century, according to the Minnesota Pollution Control Agency.
Though the season is still long enough to go ice fishing, the timing of the freeze is also important. For example, if it's not icy by the time winter break starts, some people might cancel reservations at cabins, Blumenfeld said.
'One-two punch' on snowpacks
Our analysis shows that in cities that had fewer freezing days, the coldest temperature of the season has increased by an average 5.7 degrees since 1956.
And when temperatures get warmer, that’s bad news for snowpacks.
“The warmer your atmosphere is, the more likely you’re going to get closer to that melting point, and you’re going to start seeing more of that winter precipitation falling as rain instead of snow,” said Elizabeth Burakowski, a research assistant professor at the University of New Hampshire. “That has a one-two punch on a snowpack.”
When snow falls on snow, it accumulates. But when rain falls on snow, it can accelerate melting. White snow is bright and reflective, but as it melts, it exposes darker ground underneath. This absorbs more of the sun’s energy, warming and melting the snowpack in what is known as the albedo feedback loop.
Towns and cities across the country rely on winter activities like skiing, snowboarding and snowmobiling to support their economies. Cold, snowy days are a basic requirement.
Even considering the cold chill in the East at the start of the winter, the contiguous United States had its second-warmest winter in 131 years of recordkeeping, according to the National Oceanic and Atmospheric Administration.
In January, Vail Resorts CEO Rob Katz told investors that season-to-date skier visits were down 20% compared with last year. In the Rockies, 11% of terrain was open in December.
The vast majority of resorts use snowmaking, which sustains about 1 in 6 skiable acres, to run their operations, according to a report from the National Ski Areas Association.
Though it can help during years when not enough snow falls, temperatures still need to be cold enough – a couple of degrees below freezing if the humidity is low, but ideally colder.
Colorado researchers and consultants had projected that shorter winter recreation seasons could lead to the loss of millions to tens of millions of visits annually by 2050 in the state and around the country.
Less water, more fires
Communities across the West are preparing for water restrictions this year – including those that control how often people can water their lawns, how often their sheets are washed at hotels, and whether they are served water when they eat at a restaurant.
And the effects of drought can be felt long after winter is over. A recent study found that an earlier spring snowmelt contributes to a longer fire season with more area burned, and that lower snowpack accumulation can lead to more severe fires in the West.
More ticks and mosquitoes
As the frozen season shrinks, some insects and animals are thriving – much to human dismay. The range of bark beetles has exploded, allowing them to ravage more forests.
“Because of warming, we’re getting fewer frost days which, would provide these killing temperatures for these kinds of pathogen species, so they are able to survive in these areas where historically they weren’t able to occur,” said John Kimball, an ecology professor at the University of Montana.
Ticks, which carry Lyme disease, have been marching north and west. A 2019 paper noted that most ticks are active from “the time that the snow melts in the spring until the reappearance of the snow cover in the fall.”
Increased temperatures lengthen the season when ticks are active, increase their survival rate and expand their habitat.
Lyme disease can cause rashes, fever, facial paralysis, and muscle and joint aches, according to the Centers for Disease Control and Prevention.
Some mosquitoes also benefit from warmer winters.
“They don’t regulate their own body temperature, so whatever temperature it is outside is the temperature that the mosquitoes’ body is, and its metabolism depends on that temperature,” said Erin Mordecai, a Stanford associate professor of biology.
In the U.S., West Nile virus is now the most common mosquito disease, but it wasn’t always like this. It was first discovered in Uganda in 1937 and only at the turn of the century it got to New York. According to the CDC, it’s been reported in every state since then.
The virus can cause flu-like symptoms, but severe cases can end up with hospitalizations and death.
For an upcoming paper, Mordecai and her team looked at temperature, mosquito surveillance and human case data in New York for the quarter century after the West Nile virus first appeared there.
“You kind of get to this point in the springtime, where it goes from below 16.7 (degrees C) to above, and when that point is happening has been starting earlier and ending later in the year,” Mordecai said.
The researchers found that warmer temperatures have expanded the transmission season by 20 days, a trend that was more likely to occur because of climate change.
A sweet and fickle harvest
"I always say, if you ever wanted to see God say 'Hold my beer and watch this,' you try to make maple syrup," said said Blackman’s sister Jennifer Reisenbichler, sugarmaker and co-owner of LM Sugarbush in Salem, Indiana. “This is the hardest job I've ever had, if you can call it a job, because no matter what you do, you really can't control the outcome of each season."
In parts of New England, local governments gather with residents on Town Meeting Day in early March to vote on things like town budgets. Historically, it also marked the time of year when farmers would tap maple trees for sap, but over the decades as winters have warmed, that has been shifting earlier.
“If you wait until Town Meeting Day tap, you’re probably going to lose some of the season – you're not going to capture all the sap that you could,” said Steven Roberge, who works at the forestry extension of the University of New Hampshire.
Now, tapping starts on Presidents’ Day or Valentine’ Day.
To produce sap, maples need to go through a daily freeze-thaw cycle, which is why snow is crucial to the forest. It acts as insulation to protect the tree roots from getting too cold. It also moderates warm temperatures, because if it gets too warm, it can end production sooner.
“You can imagine being in New England during colonial times and prior with Indigenous people... Sugar was probably really important,” Roberge said, adding that up until the early 1900s, most of the production was for maple sugar, not syrup, because that was easier to store.
Though the season sometimes gets compressed from two months of normal sap flow into four or six weeks, advances in technology have helped the industry keep up.
Rather than just letting sap drip into a bucket, farmers now use tubing systems with vacuums to speed up the process.
Maple sap has about 2% sugar content. It’s boiled to remove water until it hits about 67% to form syrup. Reverse osmosis, the same technology used to desalinate seawater, removes some of the water from sap and shortens the boiling process.
Research is being done on alternative syrups such as those from sycamores and birch trees – but those don’t taste the same.
Roberge remembers growing up in northern New Hampshire, where every second-grade class would tour a friend’s family sugar house to experience the iconic activity.
“If something would happen to sugar maples, it would be devastating for a lot of people financially," he said. "But I think just from a cultural standpoint, it would be a huge loss here in the Northeast.”
Thinking about how North Carolina, which has a different climate from his home state's, can produce maple syrup makes him optimistic.
“Despite the headlines of climate change, I think there’s always going to be the weather in New Hampshire that will be able to harvest sap,” Roberge said. “But it just won’t be the same as it was 100 years ago.”
Search for your county
Explore the map below to see how many freezing days we experience now compared with 1956.
How we did it
We used a daily temperature dataset from the National Oceanic and Atmospheric Administration called nClimGrid-Daily. It provides estimates for square areas about 5 kilometers wide (roughly 3 miles). For every U.S. city or town with a population over 100,000, we used the data from the grid cell closest to its center. We then identified each day that the low temperature reached 32 degrees Fahrenheit or colder. We grouped these freezing days by “water year,” which runs from Oct. 1 through Sept. 30 of the following year (think of it as the fiscal year used in climate and water research).
For each city and year (1956-2025), we measured several indicators: the total number of freezing days, the first and last freezing day of the season, the longest stretch of consecutive freezing days, and the coldest temperature recorded. To understand how these measures have changed over time, we ran linear regressions for all cities that had sufficient data, which we defined as at least one freezing day in at least half the years – mirroring methods used by Climate Central and other researchers.
This approach helps distinguish long-term changes from natural year‑to‑year variability. We also tested whether the trends were statistically significant. We repeated a similar analysis at the county level. Counties that do not experience freezes every year were included to allow for broader exploration of the data. You can read a full description of our methods and find our code on GitHub.

 Kitchen staff were hard at work at a Massachusetts Avenue Clover location in 2015. Matthew J. Lee
Kitchen staff were hard at work at a Massachusetts Avenue Clover location in 2015. Matthew J. Lee The Clover restaurant in Harvard Square in 2011.Essdras M Suarez/Globe Staff
The Clover restaurant in Harvard Square in 2011.Essdras M Suarez/Globe Staff